C# 5 Async Exception Handling
At the PDC 2010 conference, Microsoft showed their proposed asynchronous features for C# 5. There’s one particular feature I want to examine: error handling. Anders Hejlsberg showed this, but he did so fairly quickly. The feature is so elegant that it’s easy to overlook what it does for you, so I thought it would be worth a closer look.
The broad theme of the new async features is that you can write code that looks just like normal code, but which works asynchronously. For example:
private async void FetchData() { using (var wc = new WebClient()) { try { string content = await wc.DownloadStringTaskAsync( new Uri("http://www.interact-sw.co.uk/oops/")); textBox1.Text = content; } catch (WebException x) { textBox1.Text = "Error: " + x.Message; } } }
Most of this seems fairly ordinary—we’re using the WebClient class to download some text via HTTP, putting the result in a TextBox. (I tested this out in a WPF application, but it would also work in Windows Forms.) We have some exception handling, most obviously the catch block to handle a WebException. There’s no web page with the specified URL, so the server will respond with a 404 HTTP error, meaning we’ll definitely get an exception. But that’s not the only exception-related code: more subtly, there’s a using block to ensure that we Dispose the WebClient even in the face of exceptions. (As far as I can tell, WebClient doesn’t actually do anything in its Dispose, and only implements IDisposable as a result of deriving from Component. But in the absence of any documentation telling us that disposal is optional, we should always Dispose, hence the using block.)
That’s simple enough. But what’s not obvious is that this code works asynchronously. This FetchData method won’t make callers wait for the download to complete. To prove it, the button click handler that calls this method in my test application looks like this:
private void button1_Click(object sender, RoutedEventArgs e) { Debug.WriteLine("Calling FetchData"); FetchData(); Debug.WriteLine("FetchData returned"); }
Single-stepping through the code in the debugger, we get slightly surprising behaviour: as we step through FetchData, we get as far as the call to DownloadStringTaskAsync, but then FetchData returns, and we find ourselves back in the click handler—the second Debug.WriteLine runs, showing a message in the debug output window confirming that FetchData has completed, and yet single stepping revealed that it only got half way through.
There are three reasons for this. The most important reason FetchData didn’t run to completion is that it hasn’t finished fetching the data. But there are two more details that explain what it did instead. First, notice that the FetchData method declaration has the async keyword in it. This enables the new C# 5 asynchronous functionality—it doesn’t do anything in itself, but it needs to be present for us to use the new language features, such as the await keyword that appears before the call to DownloadStringTaskAsync. And that keyword is the final piece that causes this code to execute in the unusual way we saw, returning before it had really finished.
The await keyword tells the C# compiler that we need some operation to complete before the code that follows can continue. Of course, with normal synchronous methods, this isn’t something you need to ask for—it’s the default. Normally, a method will not return until it has finished its work, so any code that follows a call to that method will be made to wait. However, with asynchronous operations, it’s different—we typically make a method call to start some work, and the method returns without waiting for that work to complete.
In the example above, the WebClient.DownloadStringTaskAsync method is asynchronous—it returns without waiting for the download operation to complete. It returns a Task<string> object, a class from the Task Parallel Library (TPL) added in .NET 4. A Task<T> represents an operation which may take some time to complete, and which, if it eventually succeeds, will produce a result of type T.
The new await keyword is designed to be used with exactly this sort of asynchronous method—it lets us tell the compiler: this method is going to return more or less immediately, but we need to wait until the work it started has finished before running the remaining code.
Normally, after a call to WebClient.DownloadStringTaskAsync (or any other method) returns, you’d expect the program to continue straight on to the next line—if you wanted to wait for the task to complete before proceeding, you’d need to write extra code. You could call the task’s Wait method, but that would block, and since we’re running on a UI thread here, that would be unacceptable.
This new C# keyword, await, does something different. It doesn’t proceed to the next line, but it doesn’t block either—as I already said, our FetchData method just returns. Actually, to be a little more precise, the C# compiler generates code that checks whether the task has already completed—asynchronous APIs sometimes complete certain requests immediately. If the task is already complete by the time the method returns, the program will carry on and execute the next line as normal. But if not, it returns, but it does one more thing before returning: it sets up a callback that will be invoked once the asynchronous operation finally completes. The code that follows the await statement will only run when this callback is invoked.
To summarize: the rest of the method executes eventually, but it only does so once the operation we’re waiting for completes.
To appreciate what the compiler has done for us, let’s see what it takes to do it ourselves. Looking at just the code inside the try block for now, it’s as though the compiler has expanded that out to:
var wc = new WebClient(); Task<string> contentTask = wc.DownloadStringTaskAsync( new Uri("http://www.interact-sw.co.uk/oops/")); Action completionHandler = delegate { textBox1.Text = contentTask.Result; }; if (contentTask.IsCompleted) { completionHandler(); } else { contentTask.ContinueWith(t => completionHandler(), TaskScheduler.FromCurrentSynchronizationContext()); }
Messy, huh? In fact I’ve simplified this a little—this isn’t what the C# compiler really generates. I’m sticking with the usual idioms for Task<T> because it illustrates the intent more clearly. But even this simplified version is pretty complex. A fair amount of the complication is down to the code that detects when the supposedly asynchronous operation actually completed synchronously. In situations where immediate completion is unlikely, we could just do this:
var wc = new WebClient(); Task<string> contentTask = wc.DownloadStringTaskAsync( new Uri("http://www.interact-sw.co.uk/oops/")); contentTask.ContinueWith(t => { textBox1.Text = contentTask.Result; }, TaskScheduler.FromCurrentSynchronizationContext());
That’s safe even if the task does happen to complete immediately—Task<T> is smart enough that if you call its ContinueWith method after the task has completed, it’ll still run the completion code. But it’s still significantly messier than the first example—I’ve now had to add an explicit anonymous callback method, and I’ve also had to tell the TPL that I want that handler called via the current synchronization context. (I need this because the callback updates a TextBox, so it needs to run on the UI thread.)
So far, I’ve only really dealt with three lines of the original code. I’ve left out something very important: error handling.
The TPL helps us out with errors—Task<T> keeps hold of any exceptions that occurred while the operation was executing. Its exception handling is pretty good—even if you need to do complex, multi-step operations asynchronously, it can handle errors gracefully. But despite the amount of work the TPL does for us, back in the world of C# 4 we still need to make some changes to our code to exploit this:
contentTask.ContinueWith(t =>
{
wc.Dispose();
if (t.IsFaulted)
{
textBox1.Text = "Error: " +
t.Exception.InnerExceptions[0].Message;
}
else
{
textBox1.Text = contentTask.Result;
}
},
TaskScheduler.FromCurrentSynchronizationContext());
There are a couple of unsatisfactory things about this. First, it no longer looks like normal idiomatic C# error handling—I’ve lost my try and catch blocks. Second, I’ve had to add an explicit call to Dispose here to clean up the WebClient—I can no longer rely on a using statement. Both problems are caused by the fact that I had to split up my code to accommodate the callback required for asynchronous operation.
By using an anonymous method, I have at least managed to write code that runs in the order in which it reads, but there’s a lot of boilerplate in there now, making it more effort to write, and more importantly, harder to read. And that’s the sort of code we have to write today with C#/.NET 4 if we want to perform asynchronous work with proper error handling. But with its new asynchronous features, C# 5 will let us write the code I showed in the original example, using ordinary-looking exception handling, and it will all just work.
Here’s what I see in Visual Studio when I run the original example on a machine with the async CTP installed (and with VS configured to stop even when handled exceptions are thrown):

If we weren’t paying close attention in this debugging session, this would look like normal synchronous code that happened to throw an exception, but if we look closer, we can see that it’s stranger than that. Earlier, we saw that the FetchData method returned without waiting for the web operation to complete. A quick look at the Output panel in Visual Studio confirms this—I can see the “FetchData returned” message—and yet we’re somehow back in FetchData again.
The web operation happens asynchronously, so it only discovers problems some time after kicking off the operation. So it makes sense that the exception gets thrown some time after FetchData returns to its caller. The weird thing is that the exception was somehow thrown back into FetchData, even though that method has already returned.
This works because the C# compiler has split my code up to enable asynchronous execution, and that’s why I can find myself back inside a method that I only invoked once and which has already returned. And this reveals that the compiler has performed more complex surgery than the manual version I wrote earlier—my version just looked for the exception in the Task<string>, but here, the exception has been rethrown back into my code. (I’m not going to go into the full details, but if you’re interested, there’s a helper class in the System.Runtime.CompilerServices namespace called TaskAwaiter, and the exception is rethrown by its EndAwait method in this particular example.)
We can get a bit more insight into the exception handling by looking at the IntelliTrace panel. (This requires a sufficiently empowered copy of Visual Studio 2010—I think it’s only available on the Ultimate edition.) IntelliTrace shows us a log of interesting stuff that has happened in the debugging session:
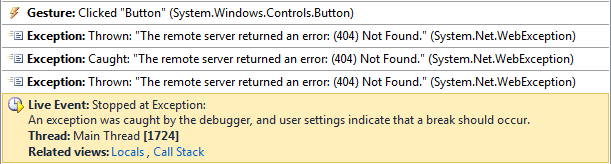
I’ve cropped this to show just the events relevant to this discussion. You can see that it began with a button being clicked—IntelliTrace automatically adds entries for various user input events. And you can see that the last entry is the exception currently being debugged—the same one as in the earlier screenshot. But you can see three more Exception entries: a throw, a catch, and another throw. Let’s look at the first one:
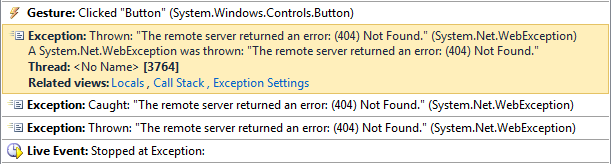
This is the original error—the point at which the exception was first thrown. Notice that the thread ID here is different. In the previous screenshot we were on thread 1724, which happens to be the UI thread in this debugging session, but in this first trace entry, the thread ID was 3764. This shows that we weren’t on the UI thread when things went wrong.
And that’s what you’d expect—under the covers WebClient depends the HttpWebRequest class, which in turn depends on sockets, which use thread pool threads for asynchronous completion notifications. So the HTTP 404 status is first detected on a thread pool thread, and that’s where the WebException is first thrown. But as you can see in the IntelliTrace log, it’s caught, and then rethrown back on the UI thread. That happens because we used the DownloadStringTaskAsync method—it makes the exception available through the Task<string> object, and the code generated by the C# compiler for the await keyword calls a helper method that detects that the task is in a ‘faulted’ state. This helper retrieves the exception and rethrows it.
The full details of this are all quite involved. The transformation that the compiler applies to your code is non-trivial. There are further complexities caused by the fact that the await keyword knows nothing about Task<T>—it goes through extension methods in this example. (The C# compiler requires the await argument to provide a helper method, called GetAwaiter, which must return an object that providers two more helpers, BeginAwait, and EndAwait. It doesn’t care whether these are instance methods or extension methods, but in this case, the class library provides extension methods that add these to Task<T>.) This makes the whole asynchronous mechanism extensible—you can use these language features in conjunction with your own classes if, for some reason, you don’t want to use the TPL. See Jon Skeet’s blog on this for more details.
But the upshot is that exception handling (not just try/catch blocks, but also using statements) work in a way that seems perfectly straightforward, despite the hoops the compiler has to jump through to make them work in asynchronous scenarios. If you’ve written much code to work with asynchronous services, and to handle errors that emerge from them, you can see how these new C# 5 language features make consuming those services far easier. I can’t wait to be able to use them.